Vector Search
Nov 29, 2020
One minute, 49 Words
获取最相似的节点
计算机只是一个电子设备的集合体,它没法像人一样感知这个世界。怎样使得计算机也能认识这个世界呢?计算机只认识数字,它只能通过数字来量化这个世界,用一组数字来表示一个事物,这样的一组数字就是一个向量(Vector)。如果一个向量由n个数字组成,它就是一个n维向量。拿目前广泛使用的人脸识别技术来说,计算机从照片或视频中提取出人脸的图像,然后将人脸图像转换为128维或者更高维度的向量。
在获取最相似的节点之前,来回顾一下高中的数学知识。在二维平面XY上有若干个点,A(1.0, 2.0),B(1.0, 0.0),C(0.0, 2.0),试问A离谁比较近一些?
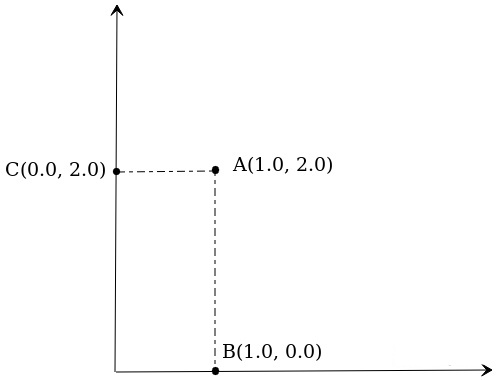
根据欧几里得的数学公式\(\sqrt{(x_0 - x_1)^2 + (y_0 - y_1)^2}\)可以计算出AB距离为2, AC距离为1,因此A离C更近一些。这就是一个最简单的向量检索,通过计算获知向量A离C更近,而AC距离更近意味着向量A和向量C更相似。
相应的,对于高维向量,假设用A和B分别代表两个n维向量,它们之间的欧式距离计算公式就变成了\(\sqrt{(A_1 - A_2)^2 + (A_2 - B_2)^2 + ... + (A_n - B_n)^2}\)
回到人脸识别问题,假设我们已有一千万张人脸的向量数据,现在给定一张人脸,怎么在这一千万张人脸中找到与目标人脸最相似的人脸?根据上面的知识,我们只需要把这张人脸的向量和一千万张人脸向量分别计算欧氏距离,距离最小的就是最相似的。
向量检索方法
向量检索有两个基本参数,一个是n,意思是拿n条目标向量去数据库中做检索。另一个是k,意思是查找离目标向量最近的前k个向量,我们一般称为top-k。
向量检索有两类方法 :存在最近邻检索(Nearest Neighbor Search,NN)和近似最近邻检索(Approximate Nearest Neighbor Search,ANN)。NN最初是用目标向量和数据库向量逐条计算距离,结果最为精确,后来又产生了相关算法(比如KD-tree),使得搜索效率大为提高,但在应对海量高维度数据时显得力不从心。ANN则是在可接受的精度条件下通过把向量分簇建立索引,大幅提高搜索效率,这也是大规模向量检索场景下所使用的主要方法。
分簇索引
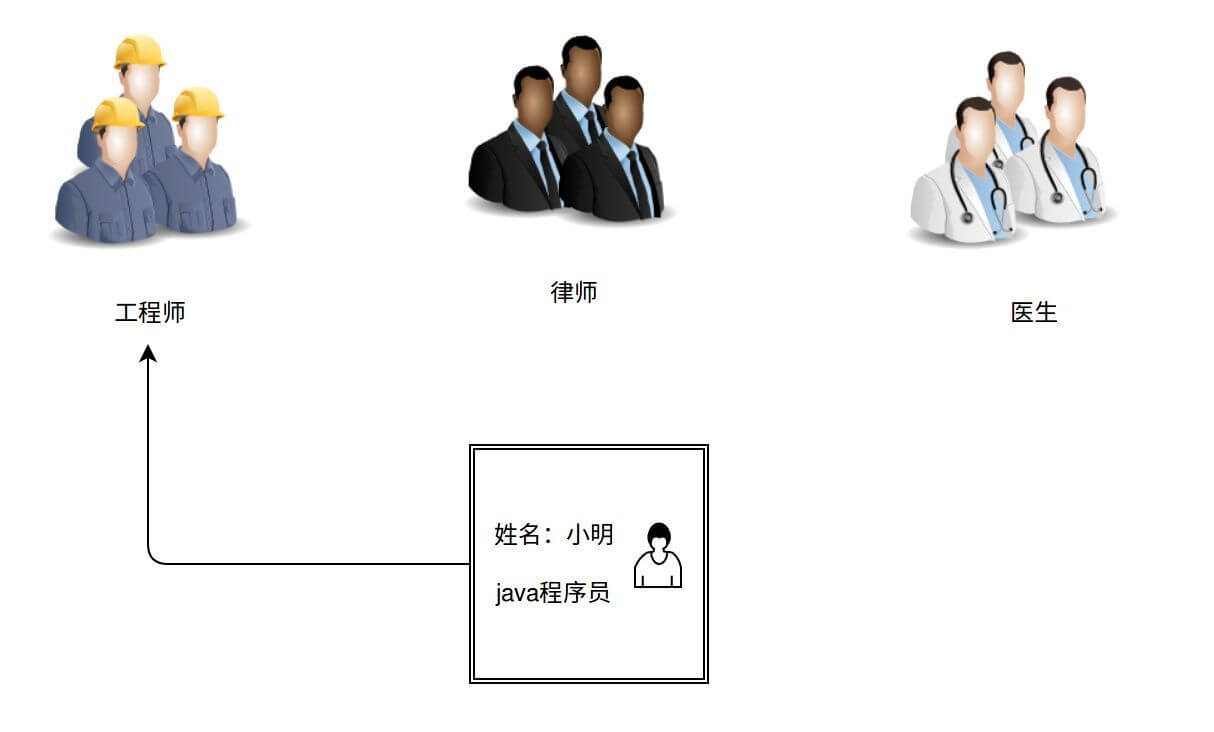
打个比方,我们先给一个城市里所有的人按照职业做一个分类,比如工程师,律师,医生,等等。现在我要找一个人,他是Java程序员,那么我们掐指一算,只要在工程师队伍里找就十有八九能找到他,不需要再去其他队伍里找了。
向量检索中典型的做法就是通过某种聚类算法把大批向量分成很多簇, 每个簇含有成百上千条向量,每个簇都有一个中心向量,当用户输入目标向量搜索时,系统先把目标向量和每个簇的中心向量做距离计算,挑选出距离比较近的几个簇,然后再把目标向量和这几个簇里的每一条向量做距离运算,最后得出距离最近的k条结果向量。
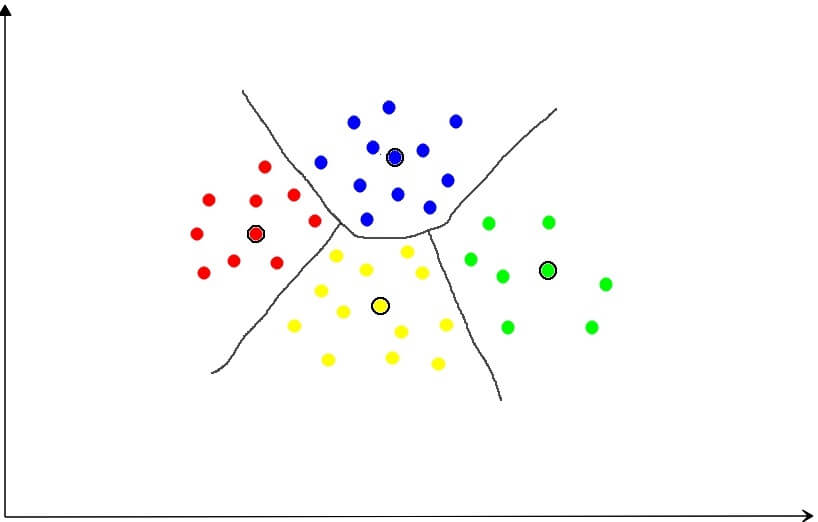
下面将以一个散点图来进行更为直观的说明。假设在二维平面上有若干个向量(点)。

通过聚类算法把它们分成若干个簇,簇的数量是可以指定的(这里以4为例),黑圈表示中心向量。
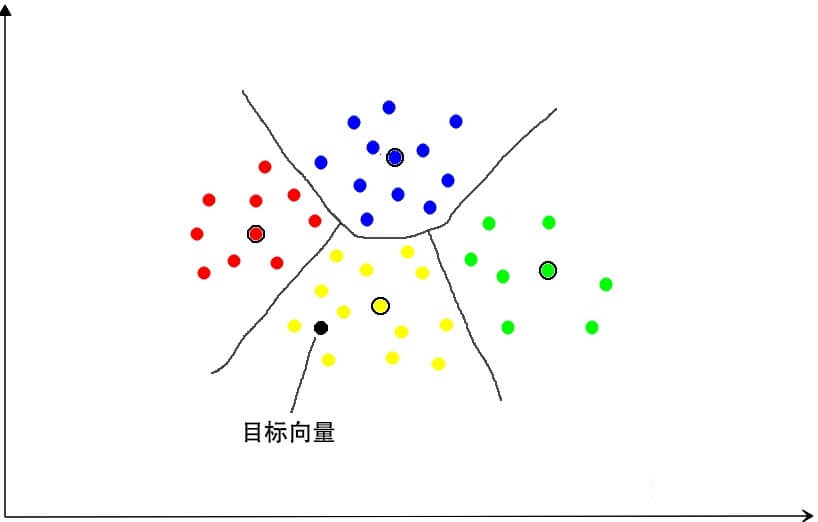
加入要检索的目标向量,根据对比计算,我们发现它离黄色簇的中心最近,那么只需要将目标向量和黄色簇里每一个向量计算距离,就可以得到离目标向量最近的那个向量。
当然,具体到实现环节会有很多种不同做法,有基于矢量量化的,基于图的,以及基于树的各种算法。
面临的问题
大规模向量检索的系统作为一个向量数据库,不但要能够支持海量数据的持久化,还要能快速地检索出用户需要的信息。生产环境中的向量维度一般起步就是128维,高一些的可达512维。我们可以算一下,对于512维度的向量,每条向量有512个数值,通常在计算机里这些数值是以float类型表示,这意味着每条向量将会占用2048字节,那么一亿条这样的向量就会用掉200GB。而生产环境中的向量数量有可能达到十亿甚至百亿的规模。
根据使用的场景,可以分为静态库和增量库。静态库就是数据固定不变的,一旦完成数据导入,基本不会再接收新的数据,这种场景主要注重检索的性能;增量库在用户使用向量检索的过程中可能还伴随着持续的数据插入,需要考虑的问题要多一些,比如数据插入后多久可见,怎样兼顾检索效率和插入效率,如何保证宕机数据不丢失等等。
目前,用于向量检索的最热门工具是Facebook开源的FAISS向量搜索库,另外,微软也开源了一个SPTAG库。用户可以无需深入了解向量聚类和向量相似性计算的算法,就能使用这些库实现简单的向量检索。但是这些只是最基础的工具库,其功能并不包括对向量数据的管理,不具备高可用性,缺乏监控手段,没有提供分布式方案,以及缺少各种语言版本的SDK等等,这也使得用户需要基于它们进行大量的开发才能满足生产环境的要求。